

Для пользователя ML-модель обычно выглядит как классический «черный ящик». И она принимает решения, значимые для бизнеса организации, таким образом, что специалисты не понимают, почему именно был сделан тот или иной вывод. Это свойство является, по сути, платой за то, что алгоритм машинного обучения умеет находить нелинейные закономерности в данных. Бум глубоких нейронных сетей, который мы переживаем сегодня, связан с принципиально новыми возможностями моделирования ситуации: вместо простой линейной регрессии, реализовать которую можно даже с помощью Excel, стало возможно использовать сложные алгоритмы, анализировать веса признаков и настраивать нейросеть на оптимальный прогноз.
В поисках лучших архитектурных решений для моделей классических алгоритмов индустрия стала использовать метод градиентного бустинга. Теоретически он предполагает использование целого набора простых моделей, постепенно исправляющих ошибки предшественников для получения конечной сильной нейросети. На практическом уровне подразумевается комбинирование слабых алгоритмов с помощью перерасчета входных данных: каждая последующая модель (она обычно имеет вид дерева решений) конструируется таким образом, чтобы придавать больший вес тем наблюдениям, которые ранее были предсказаны с ошибкой. Метод градиентного бустинга получил широкое распространение в среде датасайентистов, появились соответствующие готовые библиотеки на Python. Однако сами модели стали еще более непрозрачными, а задача получить объяснительные функции — еще более актуальной. Ее решает платформа Polymatica ML. Посмотрим далее, какие основные элементы формируют эту дополнительную ценность.
Интерпретация признаков модели
В решении Polymatica ML используется метод SHAP (SHapley Additive exPlanations), базирующийся на математической теории игр. В его основе — так называемый вектор Шепли, который отражает все возможные комбинации и варианты данных. Метод позволяет разбить прогноз на части, выявить значение каждого признака и, проанализировав все элементы вектора, понять, какие факторы модели играют самую важную роль при выборе варианта решения.
Платформа Polymatica ML обеспечивает в качестве результирующих данных не только собственно результат работы модели, но и коэффициенты, характеризующие важность вклада разных признаков в достижение этого результата. Анализ признаков дает возможность скорректировать результат модели в лучшую сторону, осознанно влияя на характеристики отдельных значимых свойств.
Тонкий анализ модели
Polymatica ML умеет работать с некоторыми внутренними параметрами каждой модели и оценивать, какое влияние они способны оказывать на конечный вывод. Основной метод такого анализа — автоматизированный эксперимент, то есть перебор различных вариантов показателей с последующим анализом итоговых метрик. На платформе Polymatica ML для этих целей реализован визуальный конструктор логики автоподбора параметров. Можно также воспользоваться готовым скриптом, встроенным в платформенное ПО, или решениями, реализующими различные известные математические методы интерпретации модели машинного обучения:
· Partial Dependence Plots (PDP, графики частичной зависимости, PD-графики) — визуализируют корреляции между целью и выбранными признаками после того, как модель обучена. Используется Python-библиотека PDPbox.
· LIME (Local Interpretable Model-agnostic Explanations) — использует механизм локальной интерпретации моделей вместо попыток интерпретировать всю модель целиком.
Также можно интерпретировать не само предсказание результата, а, скажем, разницу между двумя предсказаниями или текущим и усредненным. Тогда фактически речь идет о попытке объяснить, каким образом изменение некоторых входных признаков влияет на изменение результирующего предсказания.
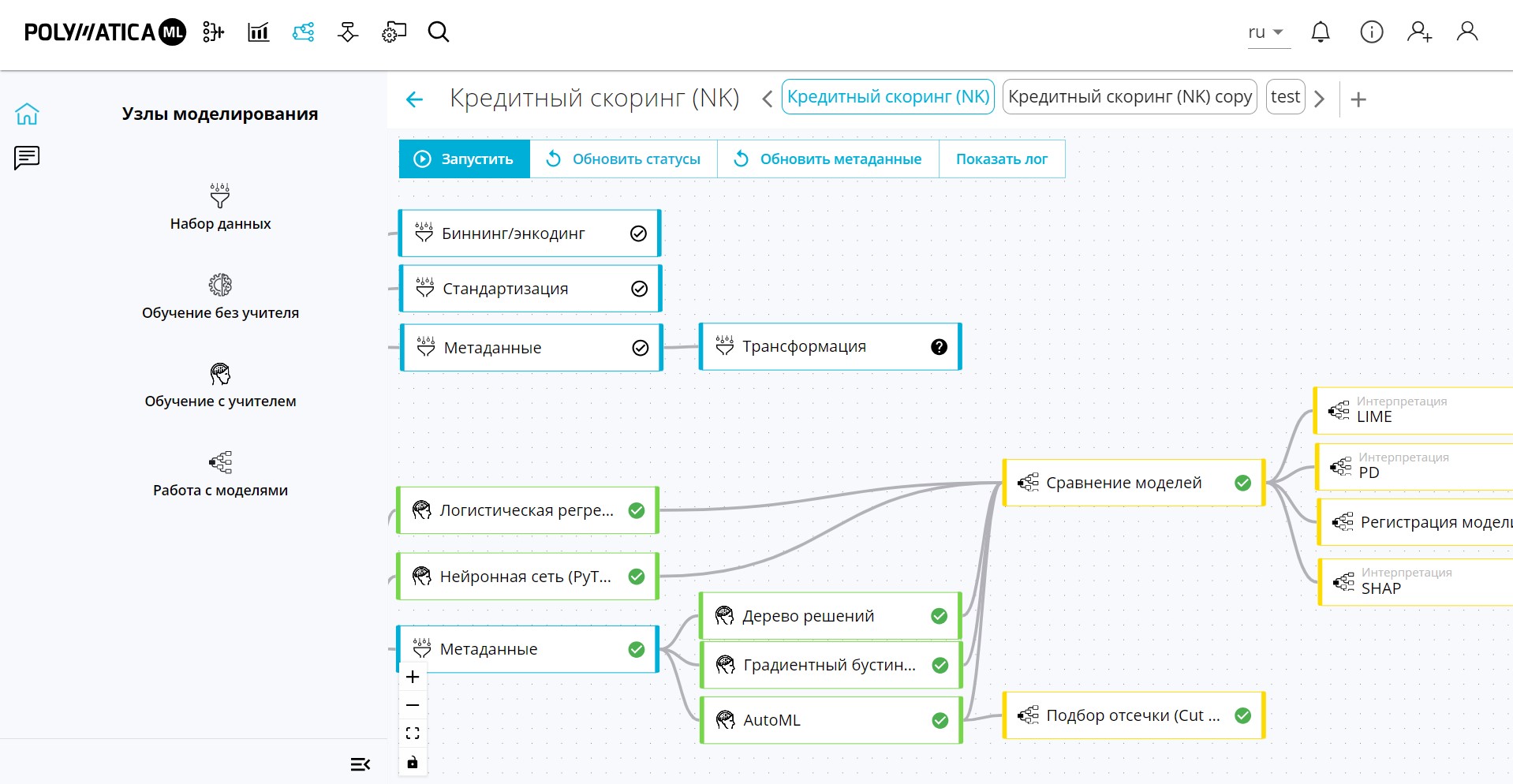
В математическом смысле методы LIME и SHAP несколько похожи — оба работают с моделью как с «черным ящиком»: изменяют данные на входе модели и анализируют изменение вывода. Опыт работы с крупными компаниями-заказчиками показывает, что все они используют в своей работе те или иные методы интерпретации признаков моделей, а автоматизированный вариант применения этих методов, реализованный в виде функционала аналитической платформы Polymatica ML, дает возможность любым другим учреждениям воспользоваться опытом лидеров.
Вместо датасайентиста или вместе с ним?
Методы улучшения объяснительной функции модели доказали свою практическую полезность. Но данная математика относится к продвинутому уровню data science, а значит, только весьма крупные организации могут позволить себе подобные штатные единицы. Функциональность решения Polymatica ML дает возможность организовать «под ключ» весь поток нужных алгоритмов: от их развертывания в виде ИТ-сервисов до интерпретации результатов с адаптацией к конкретным бизнес-пользователям. Правда, платформа Polymatica ML — это не замена специалиста по обработке данных, а отличный инструмент для радикального повышения результативности его работы. Для аналитика работа с функционалом платформы проще, чем создание составных формул в Excel. По нашим оценкам, специалисту достаточно пары дней для обучающего погружения в основы машинного обучения, после чего он сможет воспроизвести на платформе все те продвинутые математические методы анализа сложных моделей, о которых шла речь ранее.



