

Время и стоимость обучения новых моделей — главные препятствия на пути распространения глубокого обучения. Для получения действительно хорошего результата требуется повторить процесс тренировки, слегка меняя условия, сотни или тысячи раз, прежде чем он станет пригоден для практического использования.
На первый взгляд, решение Run: AI напоминает виртуализацию для традиционных вычислительных систем, но на самом деле отличается от нее. Разработчики утверждают, что полностью перестроили программный стек под глубокое обучение, чтобы преодолеть существующие ограничения и значительно увеличить скорость и эффективность обучения, сообщает TechCrunch.
«Мы соединяем разрыв между новыми формами рабочих нагрузок и железом, которое появляется на рынке, — говорит глава и сооснователь стартапа Омри Геллер. — Используя этот уровень абстракции, мы можем добиться в 100 раз большей скорости, применяя распределенные вычисления».
Он подчеркивает, что обучение станет не только эффективнее, но и удобнее: «Мы можем удвоить использование аппаратных ресурсов и передать компаниям-клиентам управление над временем и стоимостью глубокого обучения».
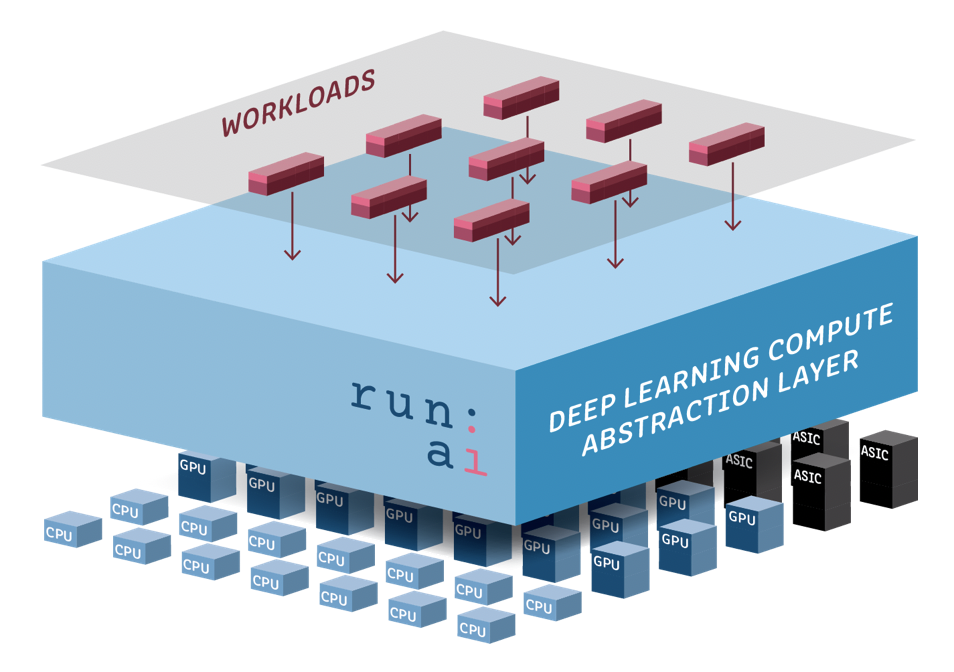
Это только часть решений, которые предлагает Run: AI. Стартап также разработал инструменты, которые анализируют модель, чтобы разбить ее на меньшие и запустить параллельно на нескольких серверах. Сервис понимает, сколько ресурсов требуется для рабочей нагрузки и каким машинам лучше их поручить. Учтено множество факторов — от доступности компьютерных ресурсов до пропускной способности сети.
Как утверждают основатели Run: AI, такой подход позволяет им обучать большие модели, превосходящие емкость памяти отдельных графических процессоров компьютера. Только что инвесторы вложили в компанию $13 млн.
Рекорд скорости обучения нейросети установили гонконгские ученые в прошлом году. Они сумели сократить время обучения ИИ ResNet-50 до 6,6 минуты. Вскоре их превзошли японцы, улучшив показатели до 224 секунд.



