

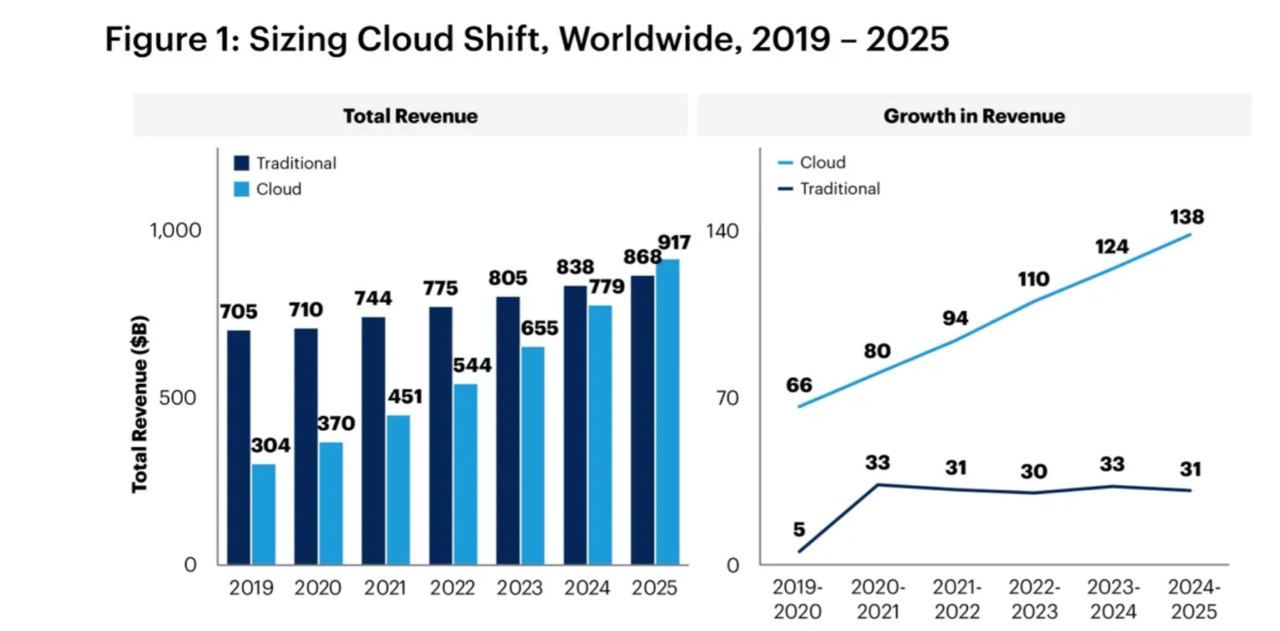
Около десяти лет назад микросервисы получили свое первое признание. По прогнозам аналитической компании Gartner, к 2025 году половина расходов на прикладное программное обеспечение, инфраструктурное программное обеспечение, услуги в области бизнес-процессов и системной инфраструктуры перейдет в облако, по сравнению с 41% в 2022 году. По оценкам компании, почти две трети расходов на прикладное программное обеспечение будет приходиться на облачные вычисления, по сравнению с 57,7% в 2022 году.
Некоторые организации могут предпочесть сначала перенести свои приложения в облако, сохраняя монолитную архитектуру, чтобы минимизировать риски и сложности миграции. Однако для некоторых приложений и компаний переход в облако может быть связан с острой необходимостью реорганизации и перестройки архитектуры для достижения более высокой гибкости, масштабируемости и надежности. В таких случаях разбивка на микросервисы может быть одним из этапов этого процесса.
— Расскажите подробнее, что мы считаем монолитом?
— На основе обширного изучения существующих исследований и публикаций по теме монолитных архитектур, я предлагаю ввести пять частичных метрик для измерения монолитности той или иной программной системы:
1. Монолитность процесса сборки измеряется количеством процессов, которые приводят к созданию исполняемых артефактов приложения. В данном случае мы учитываем только «терминальные» процессы, то есть те, которые генерируют конечные артефакты. Подготовительные процессы, генерирующие компоненты или вспомогательные элементы, в нашей метрике не учитываются. Таким образом, это целочисленное значение имеет минимальное значение 1.
2. Монолитность исполняемых артефактов. Это количество исполняемых артефактов. Например, это может быть количество бинарных файлов. Иногда, в зависимости от специфики системы, следует считать папку с «главным» бинарным файлом и вспомогательными файлами используемых библиотек и конфигураций
3. Монолитность во время выполнения. Один исполняемый артефакт может использоваться много раз (параллельно), с балансировкой с помощью некоторого балансировщика или диспетчера.
4. Монолитность хранения данных. Эта величина измеряется количеством различных систем хранения данных. Приложение хранит данные в одной базе данных или в нескольких? Если система использует файловую систему в качестве хранилища — сколько файлов и папок она использует?
5. Функциональная монолитность. В отличие от предыдущих значений, которые вычисляются более или менее однозначно, вычислить это значение зачастую очень сложно. Более того, разные специалисты могут получить разные результаты при его расчете. Для расчета необходимо проанализировать входные и выходные интерфейсы приложения, его функциональность, а также решить, на сколько независимых процессов (не вдаваясь в подробности текущей реализации) можно разбить основную функциональность приложения.
Таким образом, монолитность приложения можно грубо оценить с помощью описанных пяти положительных целых значений с минимальным значением 1.
К сожалению, не существует «золотого правила» для оценки этого пятизначного вектора. Тем не менее, как правило, в типичном бизнес-приложении значения первых четырех компонентов вектора больше или равны значению пятого компонента.
— Давайте разберемся в мифах, связанных с миграцией монолитов в облако. Многие считают, что перенос монолита в облако требует полной перестройки системы. Так ли это?
— Многие люди интуитивно ассоциируют перенос программной системы в облако с переездом на новое место жительства. И если жить в новой квартире без мебели какое-то время еще можно, то для продолжения бизнеса необходимо иметь постоянно функционирующую систему. Иными словами, миф заключается в том, что сначала нужно перенести в облако весь монолит, хорошенько его протестировать и только потом переносить туда реальный бизнес.
На самом деле это не так. Архитектурный паттерн, известный как «Призма», аналогичный «канареечным развертываниям» и A/B-тестированию, позволяет разрабатывать новые микросервисы постепенно, независимо от основного приложения и «побочных» его частей.
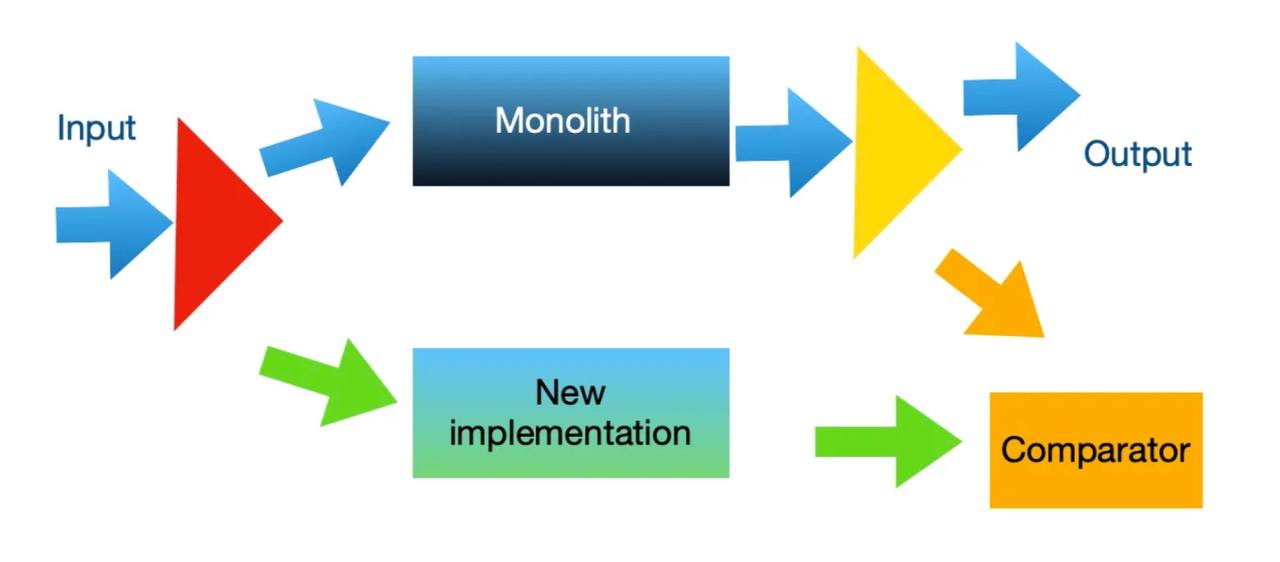
Прежде чем приступить к тестированию первой части функциональности, которую мы хотим перенести из монолита в микросервисную среду, необходимо встроить две «призмы» в процесс в производственной среде. Если система взаимодействует с внешним миром по протоколу HTTP, обе призмы могут быть реализованы в виде одного простого прокси-сервера. Различные инструменты Service Mesh, такие как Istio, предоставляют такую возможность на уровне конфигурации.
Первая призма направляет все входные данные в монолит, дублирует данные, «интересные» для нового реализованного сервиса, и отправляет продублированные данные ему. Вторая призма перехватывает выходные данные монолита, дублирует результаты работы заменяемого сервиса и отправляет дубликаты в компаратор для сравнения. Компаратор сравнивает результаты нового варианта с результатами монолита.
Таким образом, монолит работает как и прежде. Когда мы убедились, что новый сервис работает корректно и стабильно в течение некоторого времени, можно переконфигурировать обе призмы и прекратить использование старой реализации сервиса в монолите.
— Микросервисы обычно ассоциируются с небольшими модульными компонентами. Есть ли недостатки у чрезмерной фрагментации?
— То, что микросервисы должны быть маленькими, следует из самого их названия. Значит, при миграции в облако монолит должен быть разбит на большое количество маленьких частей? Примеры ландшафтов со многими сотнями или даже тысячами микросервисов вроде бы тоже говорят в пользу такого подхода.
Но в жизни все гораздо сложнее. Чрезмерная фрагментация сервисов может привести к слишком большому количеству интерфейсов между ними, сложности их обновления, проблемам при обновлении базовых библиотек и т. д. и т. п.
К счастью, в индустрии уже накоплено достаточное понимание проблемы и выработаны конструктивные рекомендации по вопросу разделения монолита на микросервисы. Приведу список основных критериев, когда такое разбиение может быть целесообразным:
1. Выделение в отдельный сервис функциональности с объективно высокой вероятностью ошибок во время выполнения.
2. Реализация компонентов с заведомо разным жизненным циклом в разных сервисах.
3. Выделение компонентов сервисов с заведомо разной ожидаемой частотой обновлений.
4. Выделение функциональности, требующей повышенной масштабируемости.
Менее очевидными являются рекомендации по отделению друг от друга функциональности с большим и малым количеством внешних зависимостей. А иногда разные микросервисы появляются просто по организационным причинам (необходимость их реализации разными командами).
— Некоторые команды полагают, что разделение монолита на микросервисы и их контейнеризация — это простой процесс. С какими проблемами они могут столкнуться?
— Перенос давно существующего монолита требует распутывания сложных автоматизированных процессов и учета различных зависимостей. Если первое заблуждение характерно для излишне осторожных команд, то это — для излишне оптимистичных.
Часто миграция монолита в облако представляется как простое «разделение» монолита на несколько частей и перемещение каждой части сначала в Docker/Kubernetes, а затем, возможно, в одну из облачных сред, например AWS или Azure. Увы, в большинстве случаев решить проблему не так просто.
Если монолит используется давно и интенсивно, он почти наверняка оброс второстепенными автоматизированными и ручными процессами, которые иногда могут быть более ценными для бизнеса, чем сам монолит. Как правило, эти процессы используют конечные или промежуточные данные, созданные монолитом, или наоборот, в некоторых ситуациях монолитным процессам требуется ручное вмешательство или помощь внешних процессов.
Поэтому, прежде чем приступить к миграции монолита, необходимо провести тщательную инвентаризацию его среды и рассмотреть способы удовлетворения потребностей этих групп. Типичными «неочевидными» процессами являются системы следующих отделов или областей:
1. Финансы (например, хранилище данных)
2. Отчеты
3. Рекламации
4. Прерывание процесса вручную в определенных ситуациях
5. Исправление неверных данных
6. Периодическая оценка ситуации
7. Конфигурация системы
8. Аудит
9. Обходные пути
С другой стороны, можно воспользоваться некоторыми стандартными компонентами, предлагаемыми облачными провайдерами, и не переносить собственные решения таких распространенных проблем, как авторизация пользователей или гибкий поиск данных одновременно в базе данных и других хранилищах. Прежде чем приступить к миграции, имеет смысл ознакомиться с рыночными предложениями вашего будущего облачного провайдера.
Разделение монолита на части обычно означает не только замену API взаимодействия между компонентами монолита, но и изменение парадигмы их взаимодействия. На практике это выливается в переход на событийно-управляемый механизм взаимодействия.
— Какие варианты дальнейших действий предлагаются при переходе на событийно-управляемый механизм взаимодействия?
— В этом случае есть три варианта дальнейших действий:
1. Использование паттерна Saga при реализации распределенных транзакций.
В основе паттерна лежит идея последовательного выполнения локальных транзакций в разных сервисах, где каждая транзакция не только обновляет локальное хранилище данных, но и инициирует следующую транзакцию с помощью сообщений или событий. В случае возникновения ошибки в одной из транзакций, сервисы выполняют компенсирующие транзакции, которые отменяют изменения, сделанные предыдущими сервисами, чтобы восстановить согласованность данных во всей системе.
Для реализации паттерна Saga существует два подхода: хореография и оркестрация. Хореография предполагает, что каждый сервис независимо реагирует на события и сообщения, не требуя централизованного управления, что упрощает архитектуру и уменьшает зависимости между сервисами. Оркестрация, в свою очередь, использует центральный управляющий компонент, который координирует взаимодействие сервисов, точно определяя, какие действия должны быть выполнены и в какой последовательности.
Несмотря на преимущества, использование паттерна Saga может сопровождаться определенными трудностями, такими как увеличение сложности управления транзакциями и тестирования системы, особенно с увеличением количества сервисов. Также важно обеспечить возможность отслеживания процесса выполнения транзакций во всей системе для упрощения отладки и мониторинга. Паттерн Saga рекомендуется использовать в тех случаях, когда необходимо гарантировать согласованность данных в распределенной микросервисной архитектуре и когда требуется возможность отката или компенсации транзакций в случае возникновения ошибок.
2. Использование паттерна CQRS при работе с распределенными данными.
User
Паттерн CQRS, или Command Query Responsibility Segregation, — это подход в проектировании программного обеспечения, который разделяет операции изменения состояния системы (команды) и операции получения данных (запросы) на два различных интерфейса. Это не только позволяет оптимизировать каждую часть под свои уникальные требования, но и значительно упрощает архитектуру вашего приложения, а также дает возможность масштабировать операции чтения и записи независимо друг от друга, что может оказаться критически важным для обеспечения высокой производительности вашей системы. Кроме того, четкое разделение между командами и запросами значительно упрощает разработку и поддержку, так как разработчикам становится гораздо проще ориентироваться в коде.
Впрочем, внедрение CQRS может привести к определенным трудностям. В частности, возрастает сложность системы, поскольку необходимо поддерживать две различные модели данных и обеспечивать их синхронизацию. Кроме того, требуется тщательное тестирование для уверенности в том, что изменения состояния выполняются корректно, а данные возвращаются актуальные и согласованные. Паттерн CQRS особенно подходит для сложных систем с высокими требованиями к производительности операций чтения и записи. Это решение находит свое применение в распределенных системах и микросервисных архитектурах, где важно четкое разделение ответственности и возможность независимой оптимизации различных аспектов системы.
3. Использование идемпотентных функций, которые позволяют вызывать их повторно в случае возникновения проблем, не опасаясь за сохраненное состояние данных.
Идемпотентность — это свойство некоторых операций или функций, при котором повторное выполнение той же операции с теми же входными данными не изменяет состояние системы за пределами первоначального эффекта. В другими словами, независимо от того, сколько раз вы выполните операцию, результат будет таким же, как и после первого выполнения. Это свойство особенно важно в распределенных системах, поскольку оно обеспечивает устойчивость системы к повторным событиям и минимизирует возможность несогласованности данных из-за дублирования обработки событий. Использование идемпотентных функций позволяет системе тщательно обрабатывать такие ситуации, гарантируя, что повторные попытки выполнения операций не приведут к нежелательным побочным эффектам или нарушениям целостности данных. Использование идемпотентных операций позволяет упростить логику обработчиков событий, так как разработчики могут быть уверены, что повторная обработка событий не повлияет на конечный результат. Также применение идемпотентности способствует повышению надежности и предсказуемости поведения системы в условиях распределенных и высоконагруженных сред, где события могут генерироваться и обрабатываться в больших объемах.
Один из способов обеспечения идемпотентности в событийно-управляемых системах — использование уникальных идентификаторов для каждого события. Это позволяет системе определять и игнорировать повторные события. Другой подход заключается в сохранении информации о состоянии обработки событий, что позволяет системе проверять, было ли уже обработано данное событие, и предотвращать его повторную обработку.
— Многие ожидают, что облачные провайдеры возьмут на себя все аспекты миграции, включая мониторинг и аварийное восстановление. Реально ли это?
— Такое заблуждение часто возникает у потенциальных пользователей облачных сервисов после просмотра рекламных роликов, общения с представителями провайдеров или чтения ознакомительной документации.
Однако в реальности всё не так гладко. По крайней мере, следующие проблемы придется решать своими силами:
1. Мониторинг
2. Аудит
3. Восстановление после катастроф.
Хотя облачные провайдеры предлагают готовые решения для каждой из этих проблем, их обычно недостаточно. Большое количество платных и бесплатных решений не сильно смягчает ситуацию. В любом случае потребуется немало времени, чтобы разобраться в возможностях предлагаемых инструментов и понять, как с их помощью реализовать свои потребности.
— Существует убеждение в том, что перенос хранилища данных в облако повышает безопасность данных компании и снижает нагрузку на внутренние ИТ-отделы. Имеют ли мегапровайдеры, такие как Microsoft или Azure, действительно более надежные меры безопасности, чем внутренние ИТ-отделы компаний?
— Безопасность часто является одной из главных задач ИТ-отделов компаний любого размера. Число утечек данных и взломов информации продолжает расти, и некоторые компании считают, что данные более безопасны, если они находятся в помещениях. Компании, выбирающие этот вариант, конечно же, должны вручную доставлять каждый патч и обновление системы безопасности во внутренние сети. Кроме того, им приходится следить за серверами, чтобы не допустить несанкционированного доступа.
Одним из главных преимуществ облачных вычислений является то, что они выполняют обновление и мониторинг безопасности за вас. Перенос хранилища данных в облако повышает безопасность данных компании, снижая нагрузку на внутренние ИТ-отделы. Кроме того, существует несколько уровней контроля за облачными данными: провайдер облачных приложений и хост данных, например Microsoft или Azure (в которых применяются более надежные меры безопасности, чем в обычном ИТ-отделе), каждый из них несет свою долю ответственности за безопасность данных.
При этом не учитываются возможные стихийные бедствия, которые могут обрушиться на компанию, например землетрясения, пожары или наводнения. Если центр обработки данных компании пострадает от одного из этих стихийных бедствий, это может стать еще большим бедствием для компании. Если компания приняла надлежащие меры по созданию резервных копий данных на удаленном объекте, то это приближается к тем же идеям, которые используются для облака. Но облако демонстрирует серьезное преимущество перед локальными решениями: в нем есть геореплицированные центры обработки данных. Если в каком-то географическом регионе произойдет катастрофа, данные компании будут в безопасности, поскольку они реплицированы на многих географически уникальных площадках.
Наконец, облачные системы безопасности часто экранируют внутренние и внешние сети. Поскольку целью большинства взломов является внутренняя сеть, поскольку пользователи непреднамеренно загружают вредоносные программы через нелицензионное программное обеспечение, создание брандмауэра, изолирующего внутреннюю сеть и предотвращающего взлом внешней сети, добавляет дополнительные уровни безопасности. То же самое работает и в обратном направлении. Если угроза исходит извне, брандмауэр предотвратит заражение и внутренней сети. Неудивительно, что 69% организаций полагаются на облачные технологии кибербезопасности для снижения рисков и повышения уровня защиты.
Но стоит заметить, что они работают с разными типами организаций с совершенно разными потребностями. Предполагать, что предлагаемые поставщиком облачных услуг средства безопасности охватывают все, что нужно вашей организации, — самый быстрый способ сделать свои данные уязвимыми.
Работа с облачным провайдером — это общая ответственность. Поставщик облачных услуг отвечает за обслуживание и обновление технической инфраструктуры, находящейся под его контролем. Организация отвечает за понимание сервисов выбранной облачной модели, их совместной работы, а также структуры безопасности и доступа в рамках всего облачного решения. Это особенно важно в многооблачных средах.



