Официальный анонс Nvidia RAD-TTS состоялся в рамках виртуальной конференции Interspeech 2021, полностью посвященной голосовым технологиям. В ходе своего выступления инженеры Nvidia заявили, что за последние несколько лет голосовые помощники — Siri, Alexa, Google Assistant и другие — заметно превзошли системы, которые отвечают за работу GPS-навигаторов. Однако, считают в компании, им до сих пор не хватает «живой экспрессии и эмоций», поэтому Nvidia решила объединить синтез речи с голосовыми возможностями реальных людей.
Платформа RAD-TTS позволяет человеку обучать модель преобразования текста в речь с помощью собственного голоса. Программные инструменты Nvidia распознают темп, тональность, тембр и многие другие показатели. Затем эти акценты накладываются на виртуальную речь и генерируют нового актера озвучивания. В компании отметили, что их цель заключалась в том, чтобы повествование соответствовало тону и стилю видеороликов.
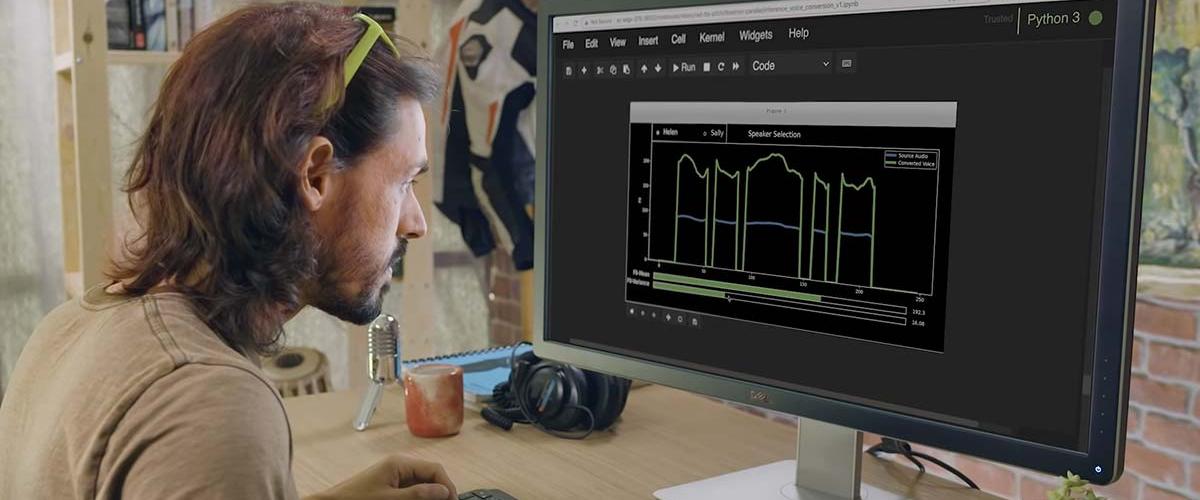
Вторая основная функция RAD-TTS, как сообщает Engadget, — это преобразование голоса, с помощью которого речь одного человека заменяется речью другого. Сервис в режиме реального времени считывает эмоциональные акценты и переносит их на заранее сохраненного пользователя.
«С помощью этого интерфейса наш видеопродюсер смог записать себя, читая сценарий, а затем использовать ИИ для преобразования своей речи в голос женского рассказчика. Используя это базовое приложение, продюсер применил ИИ в качестве актера озвучивания — настроив синтезированную речь, чтобы выделить определенные слова и изменить темп повествования, чтобы лучше передать тон видео», — сообщили разработчики RAD-TTS.
Технология была впервые применена 10 августа, когда на официальном YouTube-канале Nvidia появились видео «I AM AI». Все сценарии были написаны и записаны мужчиной, после чего платформа превратила его голос в женскую версию ведущего.
«Эти модели обучаются с использованием десятков тысяч часов аудиоданных в системах NVIDIA DGX. Разработчики могут точно настроить любую модель для своих сценариев использования, ускоряя обучение с помощью вычислений смешанной точности на графических процессорах NVIDIA Tensor Core», — добавили в Nvidia.