
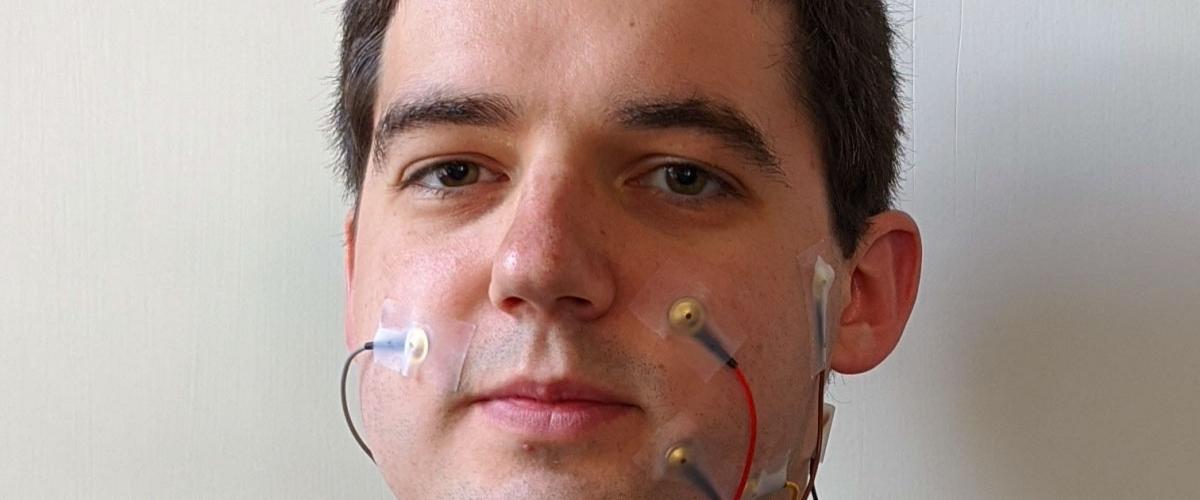
Устройство для распознавания безмолвной речи было изобретено специалистами из Калифорнийского университета в Беркли. Они использовали подход «переноса звука из вокализованной записи в бесшумную с сохранением высказывания», сообщает Venture Beat. Для последующей генерации речи они применили декодер WaveNet.
По сравнению со стандартными программами безмолвной речи, обученными с помощью вокализованных данных электромиографии, подход ученых позволил снизить коэффициент ошибок с 64% до 4% при транскрипции предложений из книг. Для того чтобы подстегнуть развитие этой области, исследователи выложили в открытый доступ почти 20 часов данных ЭМГ.
Статья, описывающая работу этой модели, была названа лучшей на онлайн-конференции по эмпирическим методам в обработке естественного языка, состоявшейся на прошлой неделе.
«Цифровое озвучивание безмолвной речи имеет широкий спектр потенциального применения, — говорится в статье. — Например, его можно использовать для создания устройства, аналогичного гарнитуре Bluetooth, которая позволяет вести телефонные разговоры, не мешая окружающим. Такое устройство также может оказаться полезным в условиях, когда вокруг слишком шумно, чтобы разговаривать, или когда важно соблюдать тишину».
Для распознавания речи тех, кто плохо говорит по-английски, специалисты Google разрабатывают сервис Project Euphonia. Чтобы настроить стандартный алгоритм на работу с «проблемными» пользователями, исследователи дополнили наборы данных небольшой выборкой, представляющей людей с БАС и акцентами.



