

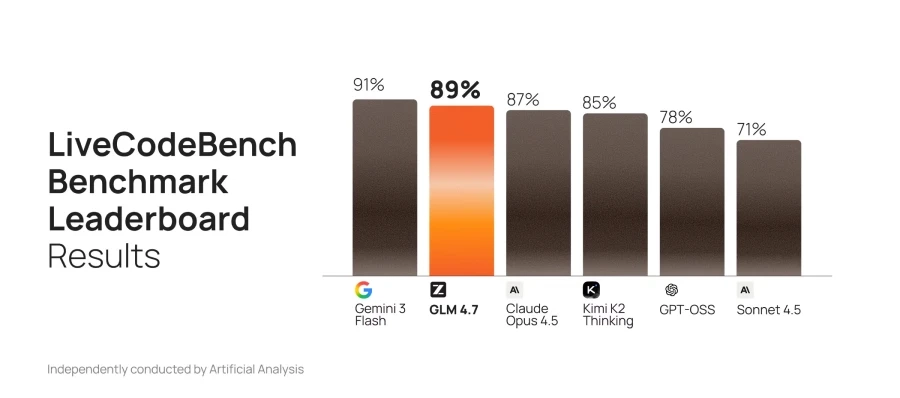
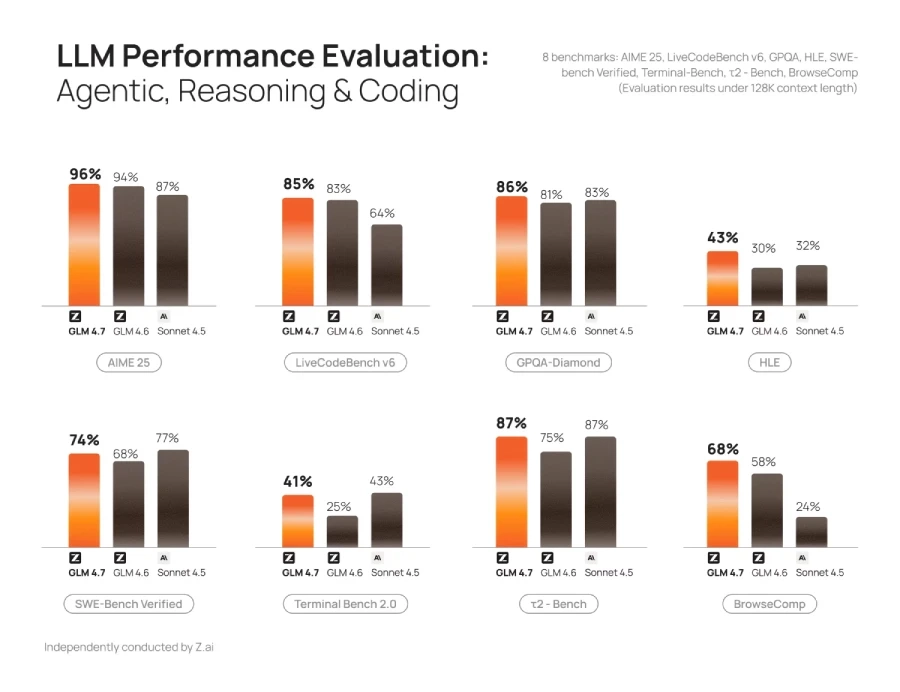
GLM-4.7 демонстрирует явный прогресс по сравнению с GLM-4.6 и конкурирует с ведущими закрытыми моделями по генерации и редактированию кода, последовательной логике и использованию инструментов. В реальных тестах для разработчиков — SWEbench, τ²bench и LiveCodeBench — новинка опережает открытые аналоги, включая DeepSeek-V3.2, по ряду ключевых показателей.
Особое внимание в GLM-4.7 уделено программированию: модель лучше понимает контекст проекта, восстанавливается после ошибок и оптимизирует код на разных этапах. Благодаря улучшенному многоязычному выводу и стабильной работе в длительных итеративных сессиях, она позволяет разработчикам ускорить процесс создания и доработки программ.
Версия 4.7 также лучше обрабатывает рабочие процессы агентов. Модель тщательно планирует действия, вызывает нужные инструменты и сохраняет контекст многоэтапных взаимодействий. В основе — «чередующееся мышление»: GLM-4.7 не рассуждает один раз в начале задачи, а анализирует ситуацию перед каждым своим действием, вызовом инструмента или ответом. Кроме того, она способна сохранять ход своих мыслей между шагами.
Главное преимущество GLM-4.7 — высокая скорость работы на платформе Cerebras Inference Cloud. Благодаря использованию кремниевых пластин модель способна генерировать код со скоростью от 1000 до 1700 токенов в секунду. Это делает её пригодной для приложений в реальном времени, где важна минимальная задержка, включая помощников по программированию и рабочих агентов.
Помимо скорости, модель обеспечивает высокое соотношение цены и качества. Пользователи получают быстрые и точные результаты при меньших затратах на инфраструктуру и меньшее время ожидания. GLM-4.7 работает в 10 раз эффективнее, чем Claude Sonnet 4.5, при сохранении точности и стабильности. Цены начинаются с $10.
GLM-4.7 совместима с существующими рабочими процессами GLM-4.6, поддерживает тот же API и легко интегрируется в текущие проекты. Разработчики могут сразу использовать улучшенные функции кодирования и работы с агентами, просто обновив модель до новой версии.



