Обучение с подкреплением — использование вознаграждения для дрессировки алгоритмов — надежный способ улучшения методики принятия решений для ИИ-агентов, если в запасе достаточно времени, данных и вычислительных ресурсов. Но иногда практичнее обратиться к другому подходу, без моделей, который позволяет ИИ действовать исходя из наблюдений за миром, пишет VentureBeat.
PlaNet изучает изображения, создает на их основе динамические модели и применяет их для получения нового опыта.
В частности, она использует латентные динамические модели, предсказывающие скрытое состояние, чтобы разобраться в таких абстрактных понятиях, как скорость объектов. Нейросеть учится посредством упреждающего формирования изображений и благодаря этому обладает способностью быстрого планирования.
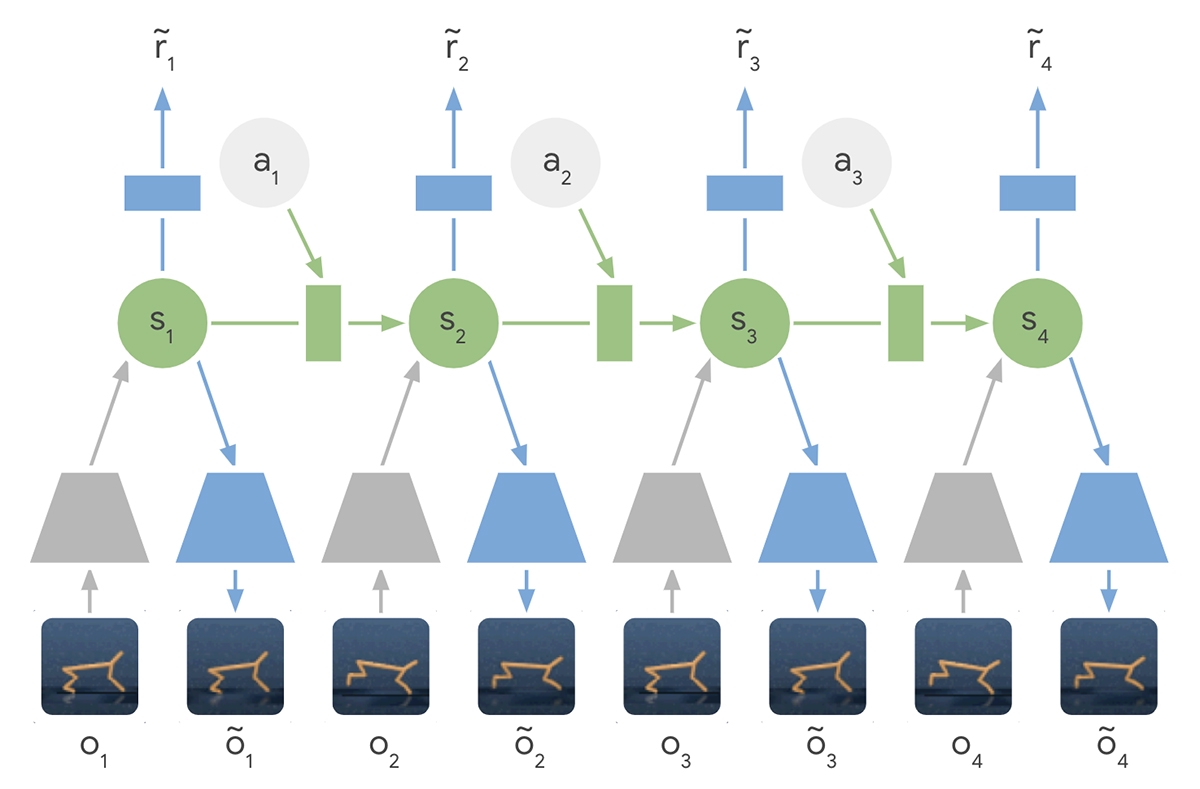
В отличие от предыдущих версий, PlaNet эффективно работает без надзирающей сети, выбирая действия при помощи планирования. Например, она может представить, как положение мяча и его расстояние до ворот изменятся от определенных действий, не визуализируя этот сценарий.
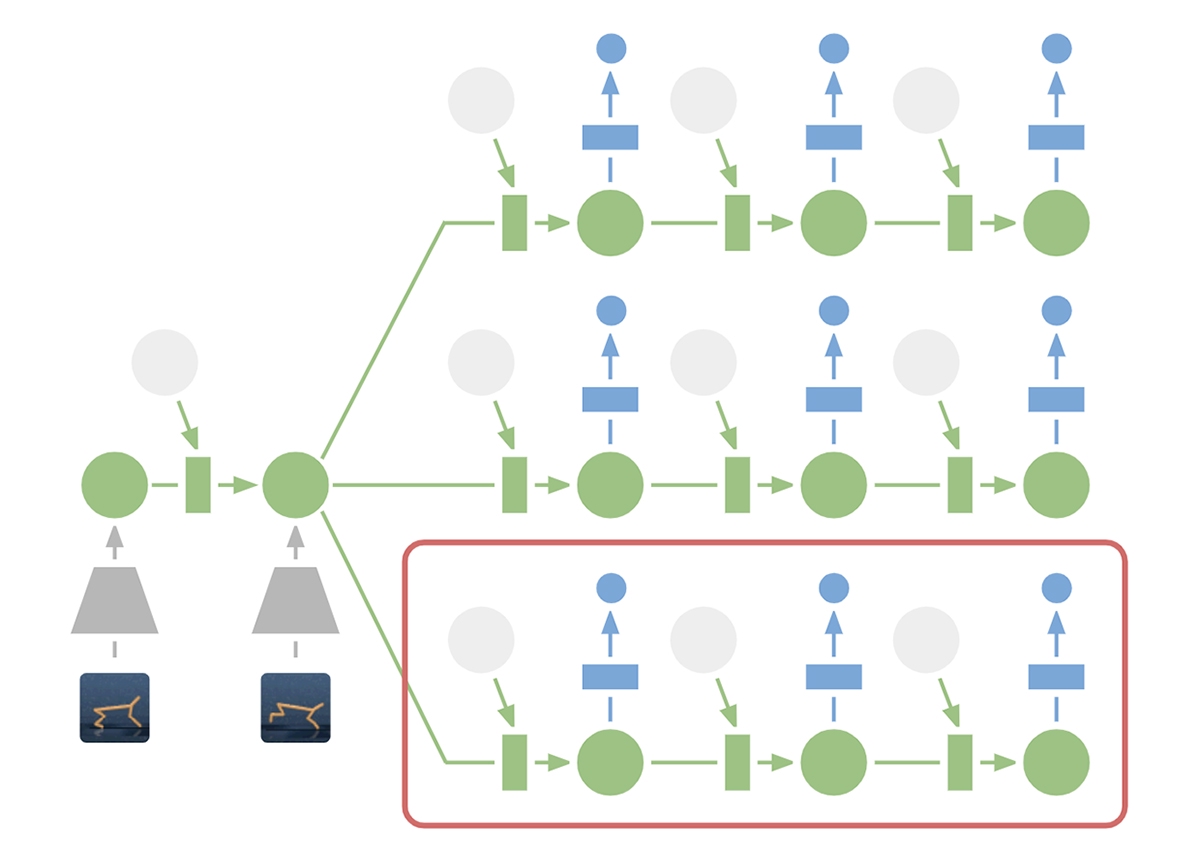
Это позволяет сравнивать 10 000 последовательностей действий с большим объемом деталей каждый раз, когда ИИ выбирает действие. Затем нейросеть выполняет самое эффективное и переходит к следующему шагу.
В испытаниях PlaNet превзошла другие безмодельные методы вроде A3C или D4PG. Более того, когда сеть поместили в случайно выбранную среду без задачи, она научилась всем шести предусмотренным там действиям всего за 2000 попыток, тогда как предыдущим ИИ требовалось примерно в 50 раз больше.
Канадский ученый Давид Дювено предложил новую модель ИИ, кардинально отличную от нейросети. Он решил отказаться от слоев и заменить их на исчисления. Его работа была признана лучшей на конференции Neural Information Processing Systems.